
Why your project’s security posture really matters

Вefore diving into methods and frameworks, it helps to frame what we’re actually checking. Think of a security posture assessment for businesses as a health check for a project: not just “are we vulnerable today?”, but “how well can we stay healthy and survive accidents over time?”. When you evaluate security posture, вы смотрите на технологии, процессы и людей одновременно: настройки облака, подход к доступам, культуру разработки, готовность реагировать на инциденты. Практический фокус здесь в том, чтобы не охотиться за экзотическими атаками, а выявлять тривиальные дыры, которые чаще всего и приводят к утечкам — забытые S3‑бакеты, слабые пароли, хаотичные права в Git и CI/CD.
Key terms without the buzzword fog
Чтобы применять практики осознанно, нужно расставить понятия. «Security posture» — это совокупность текущей защиты проекта: архитектура, конфигурации, процессы, обучение команды и мониторинг. «Cybersecurity risk assessment and compliance» — формализованный взгляд: какие риски существуют, насколько они вероятны, каковы последствия и какие требования стандартов вы уже выполняете или нарушаете. «Incident response» — всё, что происходит от момента подозрительного события до полного восстановления сервиса и анализа причин. Когда вы заказываете cyber security assessment services или делаете это сами, цель одна — понять, насколько проект выживет при реальных атаках и ошибках.
How to map your security landscape (text diagram)
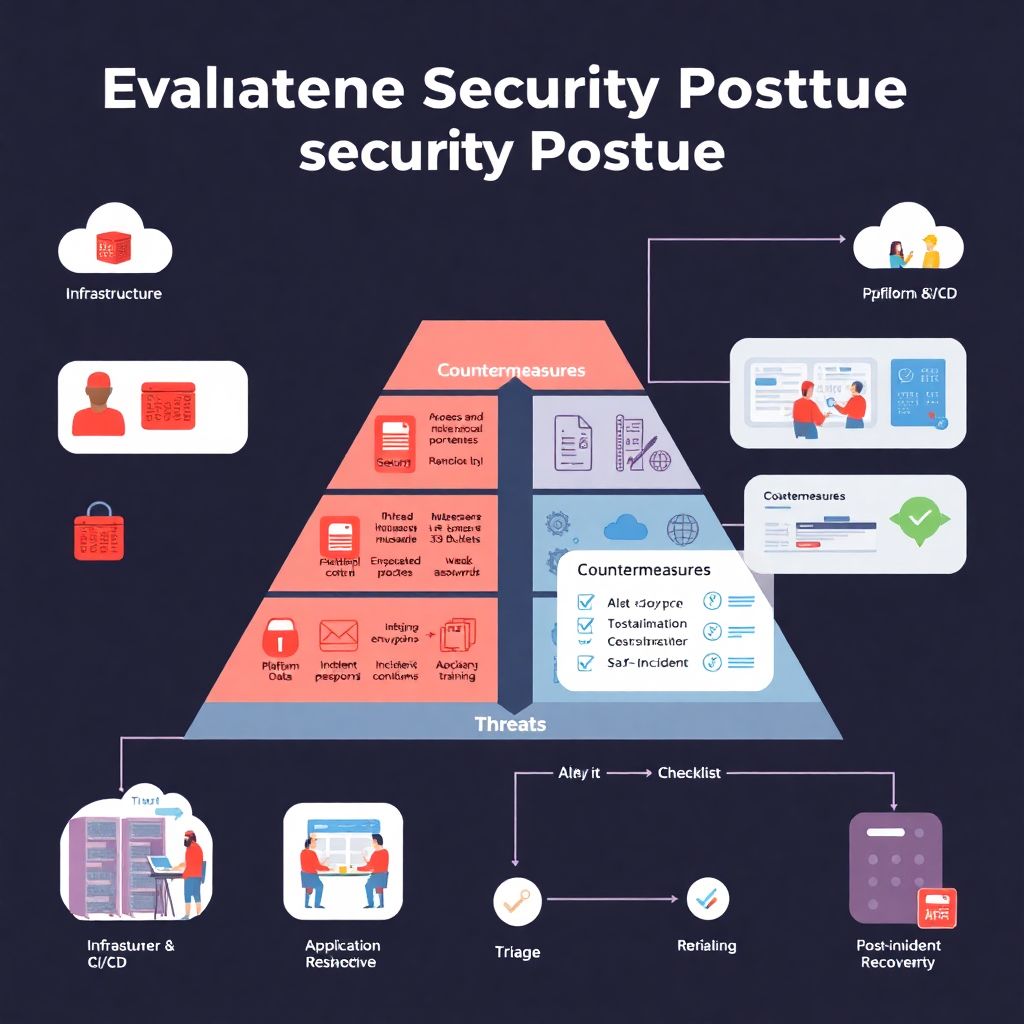
Полезно сначала визуализировать, чем вообще управлять. Представьте простую диаграмму в виде уровней: внизу «Инфраструктура», выше «Платформа и CI/CD», затем «Приложение и данные», на вершине «Люди и процессы». Слева к этой пирамиде «угрозы» (атаки, ошибки, внутренние злоупотребления), справа — «контрмеры» (контроль доступа, логирование, шифрование, обучение, процедуры). При оценке проекта вы мысленно проходите по каждому уровню и спрашиваете: «Если здесь что‑то пойдёт не так, мы это заметим? Сдержим? Быстро вылечим?». Такой текстовый макет диagrama помогает не упустить важный слой, даже если инфраструктура смешанная: on‑prem, облако и SaaS.
Step‑by‑step: evaluating a project’s security posture
Чтобы не утонуть в чек‑листах, имеет смысл придерживаться простой пошаговой схемы. На практике удобно делать так: сначала зафиксировать контекст проекта и его критичные данные, затем оценить текущие защитные меры, после этого измерить «наблюдаемость» (логи, алерты, дашборды), и только потом переходить к моделированию угроз и ручному тестированию. В отличие от разовых pentest‑отчётов, устойчивый security posture — это периодический процесс, поэтому вы сразу продумываете, как позже повторять замеры: автоматически через сканеры и policy‑as‑code, либо вручную через ревью конфигураций, архитектуры и прав в аккаунтах облака.
1. Understand scope and business impact
Первый практический шаг — описать границы оценки. Сюда входят сервисы, среды (prod, staging), внешние интеграции и типы пользователей. Одновременно определите, какие инциденты реально болезненны: потеря данных, простой API, блокировка платежей. Для небольшой SaaS‑команды достаточно простого контура: схема микросервисов, базы данных, хранилища логов, сторонние провайдеры, например managed security services provider mssp или платежные шлюзы. Это сразу подсвечивает, где безопасность критична, а где избыточные меры дадут только лишнюю сложность. В результате любые последующие решения вы соотносите с реальным ущербом, а не с абстрактными «best practices».
2. Review controls, not just tools
Дальше вы переходите к практическому «инвентарю» защиты. Важно не просто перечислить используемые продукты, а понять, какие именно контроли они реализуют: аутентификация, авторизация, шифрование, резервное копирование, сегментация сети, мониторинг. Многие команды завалены инструментами, но у них нет стройной картины, где заканчивается зона ответственности Kubernetes, где начинается облако, а где — ваши собственные скрипты. Приближённый разговорный тест: если вы не можете за пять минут объяснить, как новый разработчик получает доступ к продакшену и кто может это заблокировать, у проекта уже есть провал в текущей posture, независимо от наличия дорогих решений.
3. Compare DIY vs external cyber security assessment services
На этом этапе полезно решить, что вы делаете сами, а где привлекаете сторонних. Внутренняя оценка хороша знанием контекста, но страдает от «замыленных глаз». Внешние cyber security assessment services приносят стандартизированные методики, свежий взгляд и опыт разных отраслей, но требуют времени на погружение и бюджет. На практике рабочая модель — гибрид: команда регулярно проводит лёгкие само‑аудиты конфигураций, а внешних экспертов привлекают при крупных релизах, выходе в новые регионы или перед аудитом на соответствие требованиям. Критерий выбора простой: если вы не можете сами воспроизвести методику проверки — лучше доверить её проверенным консультантам.
Evaluating incident response readiness
Инцидент‑респонс редко проваливается из‑за отсутствия документа, чаще — из‑за его нереалистичности. Начните с честного вопроса: «Если завтра ночью кто‑то шифрует прод‑базу, что именно будет происходить поминутно?». Здесь помогают incident response consulting services, но многое можно сделать своими силами. Посмотрите, есть ли единая точка входа для сигналов (Slack‑канал, номер телефона, on‑call), кто принимает решение о блокировке ключей и отключении сервисов, как быстро вы можете восстановить данные из бэкапов и кто общается с клиентами. Любой пункт, где ответ «зависит от того, кто сейчас онлайн», — сигнал о слабом процессе.
Text diagram: from alert to lessons learned
Представьте линейную диаграмму: «Alert → Triage → Containment → Eradication → Recovery → Post‑incident review». На каждом шаге задайте три практических вопроса. Alert: откуда сигнал, кто его видит, есть ли шум? Triage: кто решает, что это реальный инцидент, а не ложное срабатывание? Containment: какие рубильники доступны — отключить токен, изолировать pod, перевести трафик? Eradication и Recovery: как вы убеждаетесь, что злоумышленник не остался в системе, и как проверяете целостность данных? Post‑incident review: кто собирает факты, фиксирует уроки и меняет процессы. Такая текстовая «схема» хорошо ложится потом в runbook.
Drills and realistic testing
Ни один план реагирования не стоит бумаги без регулярных тренировок. Минимум раз в полгода проведите учения: возьмите правдоподобный сценарий (утечка токена GitHub, компрометация сервиса логирования) и пройдите через него целиком. Не забывайте проверять не только технику, но и коммуникацию: кто пишет апдейт в статус‑страницу, кто информирует руководителей и юристов. Здесь помощь incident response consulting services особенно заметна: они приносят сценарии, о которых команда сама не подумает. В конце важно не искать виноватых, а честно зафиксировать, где процессы не сработали, и привязать улучшения к конкретным задачам и срокам в трекере.
Picking the right level of external help
Рынок переполнен вариантами: разовые аудиты, постоянный мониторинг, SOC‑as‑a‑Service. Практический способ выбрать — смотреть на зрелость команды и критичность проекта. Стартап на ранней стадии может взять лёгкий аудит архитектуры плюс базовые managed security services provider mssp, чтобы закрыть мониторинг и алерты, а всё остальное делать руками разработчиков. Крупной компании с распределённой инфраструктурой выгоднее выстроить внутренний центр компетенций и использовать внешний SOC и аудиторов лишь как усиление. Важно, что бы вы ни выбрали, сохранить внутри минимальное ядро экспертизы: люди, которые понимают и сам проект, и язык безопасности, иначе всё управление рисками превращается в чёрный ящик.
Bringing it all together in a practical checklist
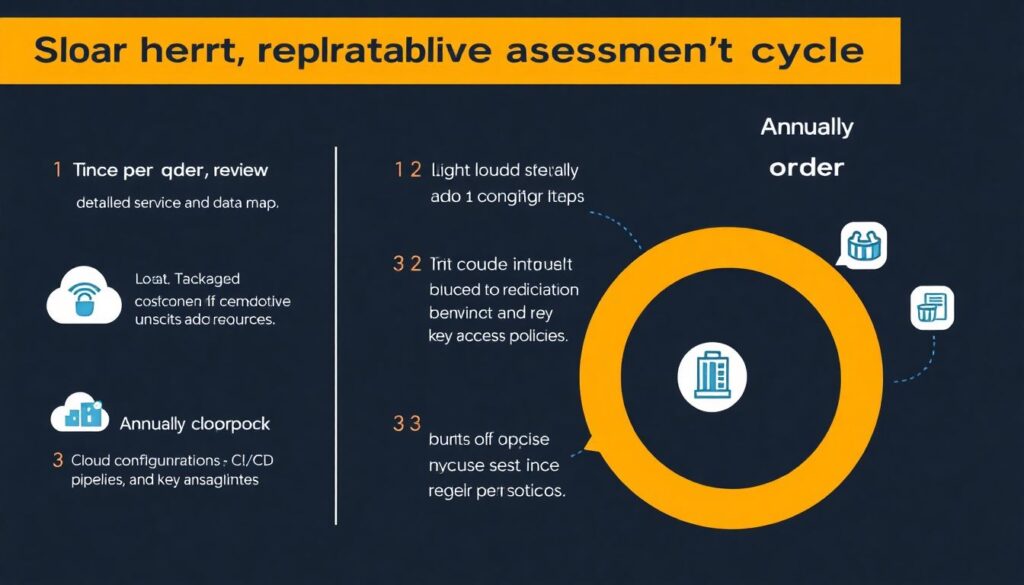
Чтобы закрепить всё в действии, удобно свести оценку в короткий повторяемый цикл. 1) Раз в квартал пересматривайте карту сервисов и данных, удаляйте неиспользуемые доступы и ресурсы. 2) Проводите лёгкий внутренний review конфигураций облака, CI/CD и ключевых политик доступа. 3) Ежегодно заказывайте внешний security posture assessment for businesses или точечный аудит критичных зон. 4) Планируйте минимум одну серьёзную тренировку по инцидентам в год. 5) После каждого инцидента или учений обновляйте runbook и метрики. Такой подход превращает разовый cybersecurity risk assessment and compliance в живой процесс, который растёт вместе с вашим проектом, а не мешает ему развиваться.